






Como os testes reCAPTCHA da Google poderiam ajudar a reduzir queimadas
João Soutto - Cientista de dados (umgrauemeio)
13/12/2022

Primeiramente, "o que é um teste reCAPTCHA?"
Você já precisou provar que era humano para algum site? Pois bem, esse tipo de teste consiste num tipo de validação que protege sites e aplicações de spam e atividades abusivas. Mas vai bem além disso...
O objetivo não é somente provar pro Google que você não é um robô. Estas associações de palavras a imagens servem como um serviço gratuito de geração de dados para treinar modelos de inteligência artificial.
E o que o incêndio tem a ver com isso? Calma, vamos por partes.
Em um mundo com infinidades de soluções que utilizam IA, o ouro da era atual tornou-se a geração de dados. No teste acima, ao clicar em imagens associadas a táxis, o usuário está indicando quais imagens contém um táxi. A ampla disponibilidade desses dados oferece oportunidades para o treinamento de diversos algoritmos.
Para entender o porque disso, é interessante o conceito de aprendizado supervisionado (supervised learning). Esta é uma técnica para elaborar algoritmos de aprendizado de máquina (machine learning) que busca classificar dados com base na coleta de padrões ou recursos que caracterizam as diferentes classes.
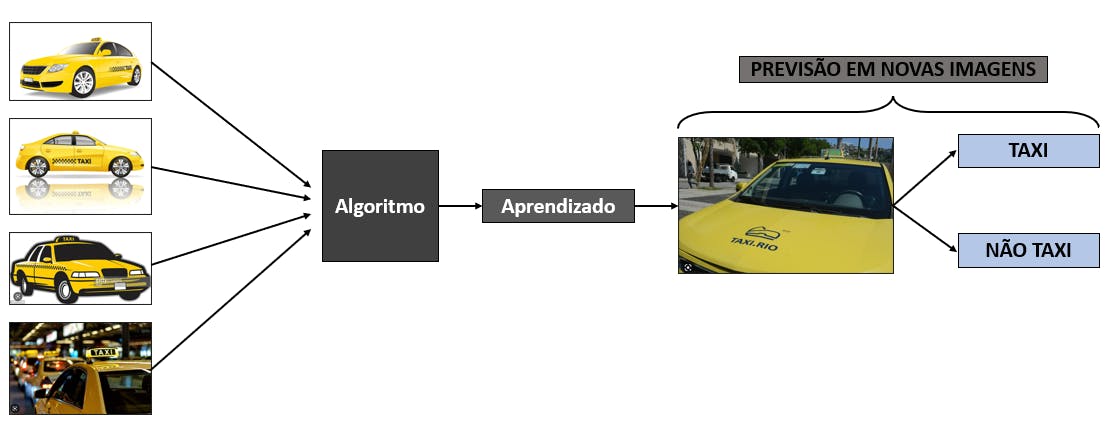
As classes representam um grupo de objetos com características, padrões ou recursos similares. No exemplo citado ao longo deste artigo, a classe seria justamente o táxi.
Para fazer isso, um modelo de aprendizado de máquina supervisionado é fornecido com muitos dados rotulados, chamados de dados de treinamento. Dados rotulados são aqueles que já contam com alguma identificação de classe, justamente por essa razão é considerado supervisionado, já que um humano precisa rotular esses dados. Este algoritmo então aprenderá os recursos associados a uma classe para que possa classificar novos dados.
Voltando aos táxis para tornar esse entendimento mais palpável: os dados rotulados seriam justamente a associação de imagens às classes presentes e os padrões similares seriam, por exemplo, a cor amarela presente na maioria dos táxis.
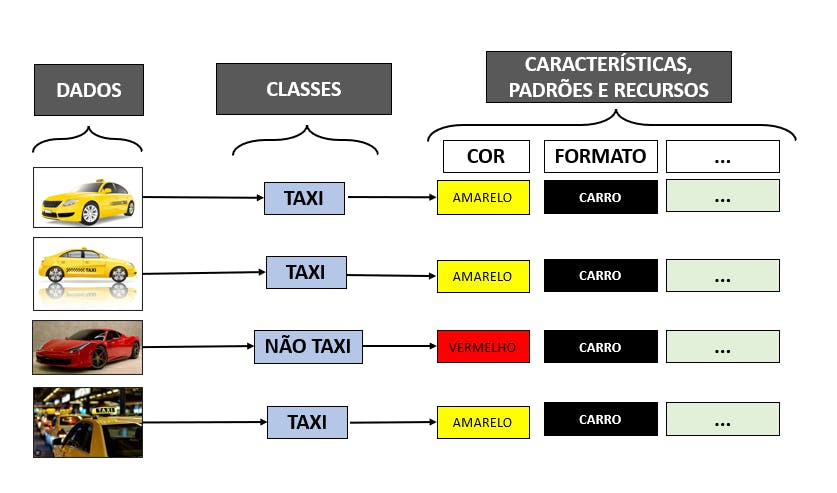
Bom, tendo isso em vista e sabendo que geralmente são necessários milhares ou milhões de dados cuidadosamente rotulados para se atingir um bom modelo, quem vai fazer o trabalho de formiguinha para classificar todos os dados? VOCÊ.
Sim, somente um ser humano poderia fazer isso. Inclusive, em muitos casos, utilizasse de ferramentas para geração gratuita desses rótulos. É onde entra o Google com a ferramenta reCAPTCHA.

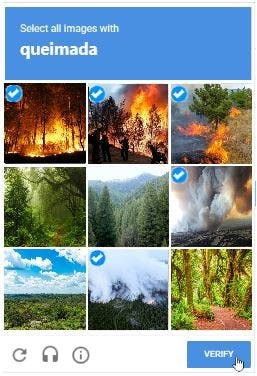
O teste apresenta imagens já rotuladas corretamente como descriminado na figura acima (seleção 1, representando as imagens onde há táxis, e seleção 3, grupo de imagens sem a presença de táxis).
No entanto, também coloca ao menos uma imagem que ainda não há confirmação da presença do objeto (seleção 2, na figura acima).
As imagens já rotuladas servem de fato para definir se é um humano que esta controlando as ações da sua máquina ou um robô programado para isso.
As outras são classificações gratuitas que os usuários fornecem.
Esses novos dados rotulados podem servir de insumo para um algoritmo de reconhecimento de táxis.
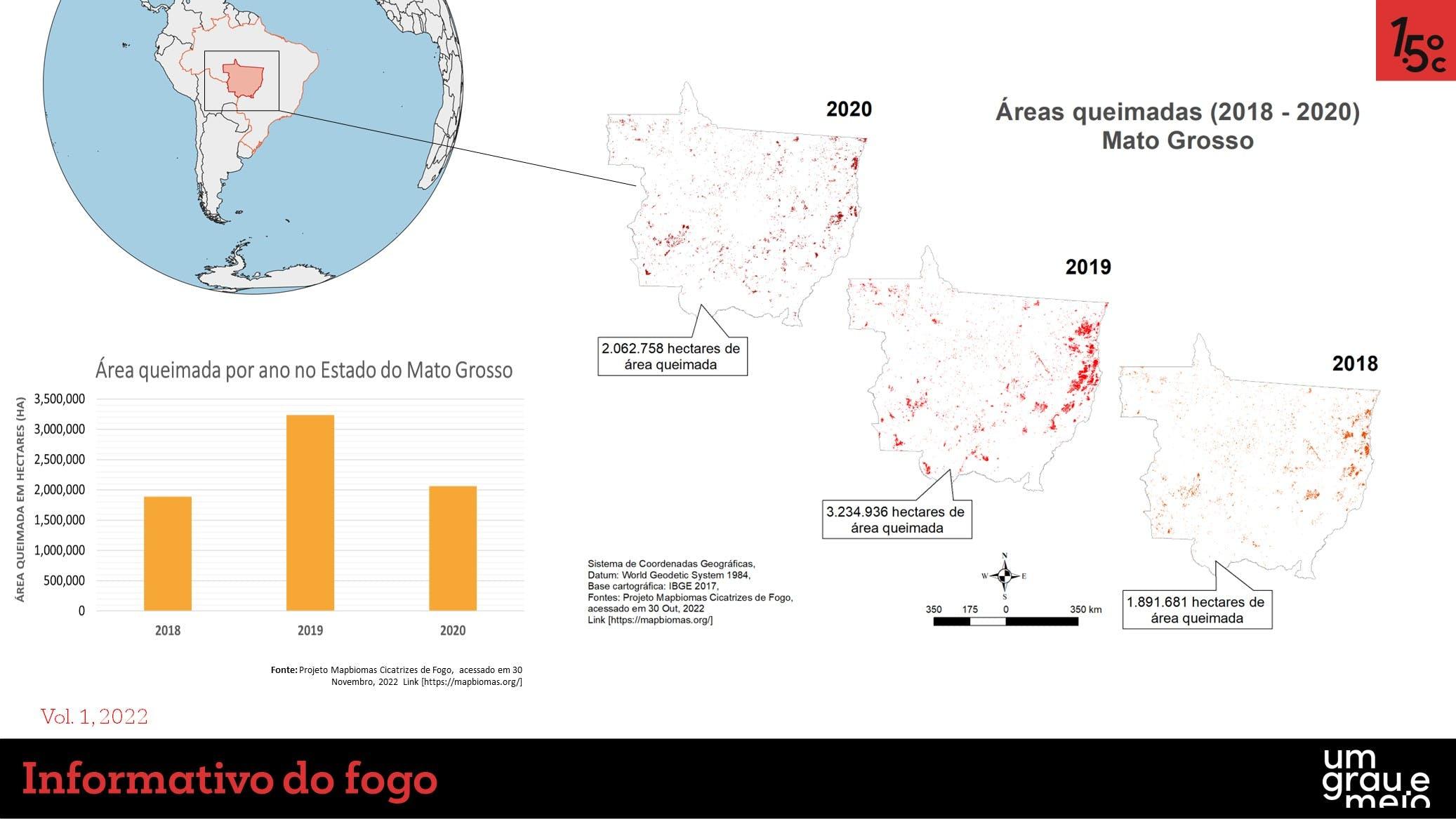
Isto aplicado, por exemplo, à imagens de incêndio florestal, poderia auxiliar no treinamento de algoritmos de detecção prévia de queimadas, aumentando a eficiência de combate das brigadas e economizando recursos utilizados devido a um combate em fases inicias do fogo. O reCAPTCHA ficaria mais ou menos assim:
Com um propósito desses, com certeza você não se incomodaria em responder, de vez em quando, se você é um robô ou não, né?
Este é o primeiro de uma série de artigos que discorrem sobre combate a incêndios, monitoramento florestal e inteligência artificial aplicada a imagens.








Quem acredita


Helena Conci Gaspari, 110
Jundiaí, SP - 13209-810





